どうもはじめまして。 muryoimpl です。
前回のエントリ 食べチョクの自動テスト改善活動 〜これまでとこれから〜 で、自動テスト改善チームが発足したことを書きましたが、今回はその活動の中で実施した、RSpec による自動テストのカバレッジのデータ収集の自動化と、そのデータを利用した可視化について書きたいと思います。
これまではどう可視化していたか
食べチョクは Ruby on Rails で動いており、バックエンドの自動テストは RSpec を使って書いています。
テストカバレッジは定番の SimpleCov で計測して結果を HTML に出力し、テストケースごとの実行情報は RSpec JUnit Formatter を使って XML として出力して、GitHub Actions でそれらの情報を Code Climate に送信していました。
また、可視化という点では、以前ビビッドガーデン Advent Calendar 2021 で私が書いたエントリ の画像のように、テストカバレッジを Google スプレッドシートに記録してグラフ化し、変化が見れるようにしていました。
これまでも現状のテストカバレッジは確認できてはいたのですが、自動テスト改善チームが発足したときのミーティングで以下のような意見が出て、改善することにしました。
テストカバレッジをクエリで見えるようにしたい
クエリを書いてデータを取り出せるようにしておけばいろいろな分析ができる
テストの足りていない箇所の洗い出しが誰でもできる
手作業で記録するのは飽きた
属人性や反映タイミングもまちまち
自動化していつでも誰でも確認できるようにしたい
Redash で可視化できるようにデータを取り込めるようにする
食べチョクでは Redash を既に利用しているので、ここにデータを投入さえできれば後はクエリを書いてグラフ化するのも組み合わせてダッシュボード化するのも自由にできます。ではデータをどう準備するかということになるのですが、以下の戦略を採用することにしました。
GitHub Actions でテストが実行されたら、SimpleCov で算出したテストカバレッジの情報をCSV化し、BigQuery に送信する
GitHub Actions でテストが実行されたら、RSpec JUnit Formatter で出力した XML からテストの実行時間情報を取り出してCSV化し、これを BigQuery に送信する
BigQuery のデータを Redash と連携する
3 については、BigQuery をデータソースとして Redash で扱う仕組みが既にあるので、1 と 2 の仕組みを用意すればよいことになります。
1 と 2 についても、元となる情報は既にあるので、必要な情報を読み出して加工し、CSV にするだけです。
1. SimpleCov が収集したテストカバレッジを CSV 化する
SimpleCov には収集したカバレッジ情報を出力する Formatter の仕組みが用意されています。この Formatter を独自に用意して CSV を出力します。
今回はテスト関連ということで spec/support 以下に simpelcov_bq_formatter.rb というファイル名で Formatter を配置しています。
format メソッドが SimpleCov から受け取る引数の result には、全体、ファイル毎、グループ毎にまとめたテストカバレッジの情報が詰まっています。これを利用して CSV を作ります。今回は全体のテストカバレッジ情報と、各ファイル毎のテストカバレッジ情報をそれぞれ出すことにしたので、全体のほうのファイル名は "All Files" という名前にしてレコードを作っています。
require " csv "
module SimpleCov
module Formatter
class BqFormatter
ALL_FILES_NAME = " All Files " .freeze
def format (result)
job_id = ENV [" JOB_ID " ]
created_at = bq_datetime_format(result.created_at)
CSV .open(File .join(output_path, " coverages_for_bq.csv " ), " wb " ) do |csv |
csv << [
job_id,
branch_name,
created_at,
" All Files " ,
" All Files " ,
percentage(result.source_files.covered_percent),
result.source_files.never_lines,
result.source_files.lines_of_code,
result.source_files.covered_lines,
result.source_files.missed_lines,
]
result.groups.each do |group_name , source_files |
source_files.each do |f |
csv << [
job_id,
branch_name,
created_at,
group_name,
short_filename(f.filename),
percentage(f.covered_percent),
f.lines.size,
f.lines_of_code,
f.covered_lines.size,
f.missed_lines.size,
]
end
end
end
end
def output_path
SimpleCov .coverage_path
end
private
def short_filename (filename)
filename.sub(SimpleCov .root, " . " ).gsub(%r{^\. / } , "" )
end
def bq_datetime_format (datetime)
datetime.strftime(" %Y-%m-%d %H:%M:%S " )
end
def percentage (percent)
percent.round(2 )
end
def branch_name
ENV [" GITHUB_REF " ]&.sub(%r{ refs/ .+ / } , "" )
end
end
end
end
JOB_ID という環境変数は、GitHub Actions の github コンテキストの情報 で構成されています。どの PR と紐づくのか判別できるように github.run_id、github.run_number を使っていますが、GitHub Actions の Job を再実行しても これらは変更されないので、github.run_attempt を加えて一意性を出しています。
RSpec の実行は並列で行っているので、扱いやすいようにカバレッジの結果を 1 つにマージします。GitHub Actions の step として、SimpleCov の結果をマージするための設定を書いた Ruby のファイルを実行して集約しています。このときに、先ほど登場した環境変数 JOB_ID を設定して渡します。
jobs :
...
report :
...
steps :
...
- name : Merge coverage files
env :
RAILS_ENV : test
JOB_ID : ${{ github.run_id }}-${{ github.run_number }}-${{ github.run_attempt }}
run : bundle exec ./bin/merge_simplecov_results.rb
...
bin/merge_simplecov_results.rb では出力先と複数の Formatter を指定しています。
#!/usr/bin/env ruby
require " simplecov "
require " simplecov-html "
require " simplecov_json_formatter "
require_relative " ../spec/support/simplecov_bq_formatter "
SimpleCov .collate Dir [" coverage/.result-*.json " ], " rails " do
formatter SimpleCov ::Formatter ::MultiFormatter .new([
SimpleCov ::Formatter ::HTMLFormatter ,
SimpleCov ::Formatter ::JSONFormatter ,
SimpleCov ::Formatter ::BqFormatter ,
])
add_group " Forms " , " app/forms "
add_group " Services " , " app/services "
add_group " Decorators " , " app/decorators "
end
これで SimpleCov の収集した情報を CSV として出力するようになりました。
2. RSpec JUnit Formatter で出力した XML から CSV を作成する
RSpec JUnit Formatter を導入して、RSpec を実行するコマンドに --out をつけてテストケース毎の結果を XML として出力しています。これを SimpleCov のときと同様に、GitHub Actions 上で読み込んで CSV に加工します。
先ほど出力した SimpleCov の CSV (coverages_for_bq.csv) を使うので、テストカバレッジの CSV を作成した後の step で実行するようにしています。
- name : Merge coverage files
env :
RAILS_ENV : test
JOB_ID : ${{ github.run_id }}-${{ github.run_number }}-${{ github.run_attempt }}
run : bundle exec ./bin/merge_simplecov_results.rb
- name : Create CSV file for BQ
run : |
bundle exec ./bin/export_spec_execution_time.rb
env :
JOB_ID : ${{ github.run_id }}-${{ github.run_number }}-${{ github.run_attempt }}
XML の path を Dir.glob で取得して Nokogiri で読み込み、内容を CSV として出力しています。
以下の処理では、XML に含まれる spec ファイル名から対応する app のファイル名を算出するために coverages_for_bq.csv を読み込んだり変換したりしていますが、単純に結果を CSV に出力するためならば不要でしょう。実際、変換処理が長くなったので、ここでは省略しています。
#!/usr/bin/env ruby
require " csv "
require " nokogiri "
require " simplecov "
require_relative " ../spec/support/simplecov_bq_formatter "
class SpecExecutionTimeExporter
NODE_REGEXP = /\A junit-rspec- (\d+)\. xml \z/
def initialize
@xmls = Dir .glob(xml_glob_path).map do |xml_path |
NODE_REGEXP =~ File .basename(xml_path)
node_number = Regexp .last_match(1 )
[node_number, Nokogiri ::Slop(File .read(xml_path))]
end
@csv = CSV .read(csv_path)
end
def to_csv
CSV .open(File .join(output_path, " spec_execution_time_for_bq.csv " ), " wb " ) do |csv |
@xmls .each do |node_number , xml |
suite = xml.testsuite
suite.testcase.each do |c |
app_fname = app_filename(c[" file " ])
csv << [
job_id,
app_fname,
node_number,
filename_dict.key?(app_fname),
c[" name " ],
c[" time " ],
]
end
end
end
end
def filename_dict
@_filename_dict ||= @csv .each_with_object({}) do |row , acc |
app_filename = row[4 ]
acc[app_filename] = 0.0
end
end
def job_id
@_job_id = ENV .fetch(" JOB_ID " , nil )
end
def xml_glob_path
File .join(SimpleCov .coverage_path, " .. " , " tmp " , " junit-rspec-*.xml " )
end
def csv_path
File .join(SimpleCov .coverage_path, " coverages_for_bq.csv " )
end
def output_path
SimpleCov .coverage_path
end
private
def app_filename (spec_filename)
return spec_filename.sub(%r{^\. /spec } , " spec " ) if spec_filename.start_with?(" ./spec/system " )
name = spec_filename.sub(%r{^\. /spec/ } , " app/ " ).sub(/ _spec \. rb $/ , " \.rb " )
-- ファイル名変換が長いため、 中略 --
name
end
end
exporter = SpecExecutionTimeExporter .new
exporter.to_csv
3. 出力した CSV を BigQuery に送信する
CSV ファイルを作成したので、後は BigQuery のテーブルにロードするだけです。
google-github-actions/auth と、google-github-actions/setup-gcloud を使って、認証し、bq コマンドで CSV をロードします。
steps :
...
- name : Setup Google Cloud Auth
if : ${{ success() && github.ref_name == 'develop' }}
uses : google-github-actions/auth@v0
with :
credentials_json : '${{ secrets.GOOGLE_CREDENTIALS }}'
- name : Setup Google Cloud SDK
if : ${{ success() && github.ref_name == 'develop' }}
uses : google-github-actions/setup-gcloud@v0
- name : Publish Spec Report to BQ
if : ${{ success() && github.ref_name == 'develop' }}
run : |
bq load --source_format CSV tabechoku_dev_tools.tabechoku_rspec_coverages ./coverage/coverages_for_bq.csv
bq load --source_format CSV tabechoku_dev_tools.tabechoku_rspec_execution_times ./coverage/spec_execution_time_for_bq.csv
全てのテスト実行の結果を取り込んでいるとさすがに煩雑になるので、default branch にマージされたときのみロードするようにしています。
Redash でクエリを作ってほしい情報を見られるようにする
データを取り込んでしまえば、後は SQL を書いてグラフ化するだけです。各種グラフを Dashboard 化していつでも結果を確認できるようにしています。
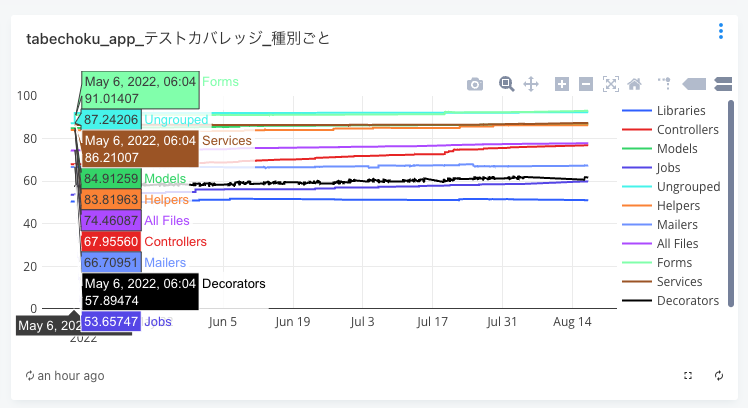
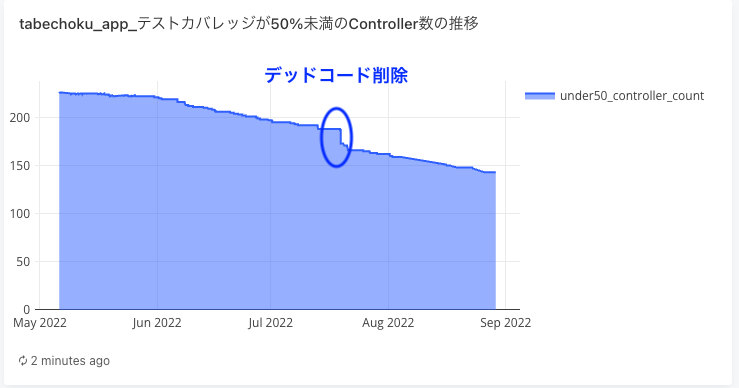
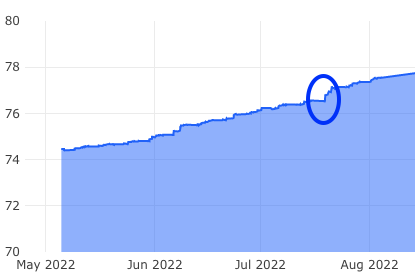
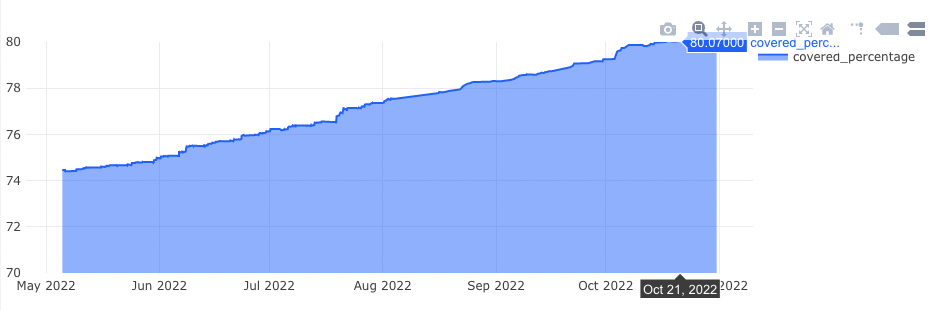
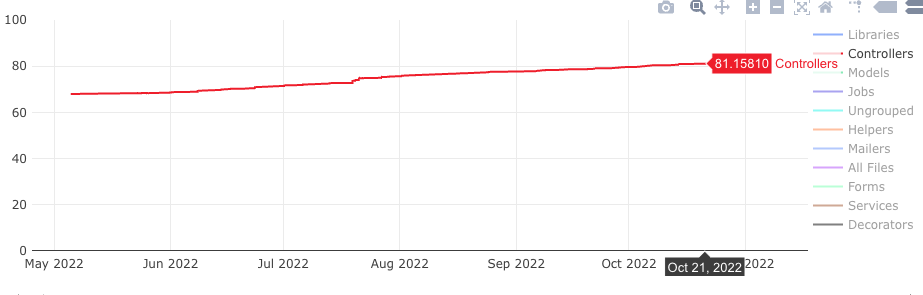
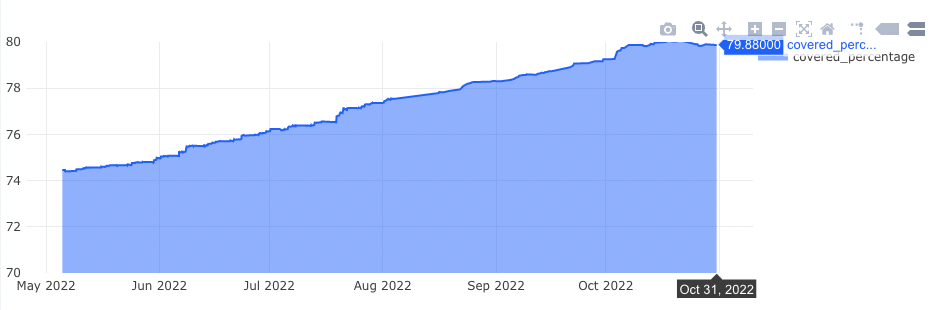
食べチョクでは、テストの実行時間、グループ毎のテストカバレッジに加え、テストカバレッジがしきい値より低い app ファイルの一覧を出力して、テスト追加対象のファイルが見えるようにしています。これにより、テスト追加対象のファイルと、テスト追加による成果の認知が容易になりました。
今回のデータを使った Redash の Dashboard
既存のデータをクエリで取捨選択、加工を可能にしたことで、単純なテストカバレッジや実行時間だけでなく、目的に沿った情報を自由に取得・表示することができ、有効活用できるようになりました。
今後は対応の成果差分がわかりやすくなるようにグラフを改善したり、通知を活用することでモチベーションが上がるかたちでテスト改善を進めていければと考えています。
まとめ
既存のテストカバレッジの情報とケース毎の実行情報を GitHub Actions 上で加工して CSV 化し、BigQuery にロードすることで、Redash と連携して現状を可視化、分析できるようにしました。
元々ある仕組みと情報を利用してデータの形式を変換してクエリを書けるようにしたことで、要求に合った情報を取り出すことができるようになり、可視化も容易になりました。このデータを活用しつつ、テストカバレッジ向上のモチベーションが上がるかたちでテスト改善活動を進めていければと考えています。
最後に
食べチョクを運営しているビビッドガーデンでは、一緒に働く仲間を募集しています。ご興味のある方はこちらの RECRUIT からどうぞ。