はじめまして。食べチョク(株式会社ビビッドガーデン)のデザイナー千田です。
はじめまして。食べチョク(株式会社ビビッドガーデン)のデザイナー千田です。
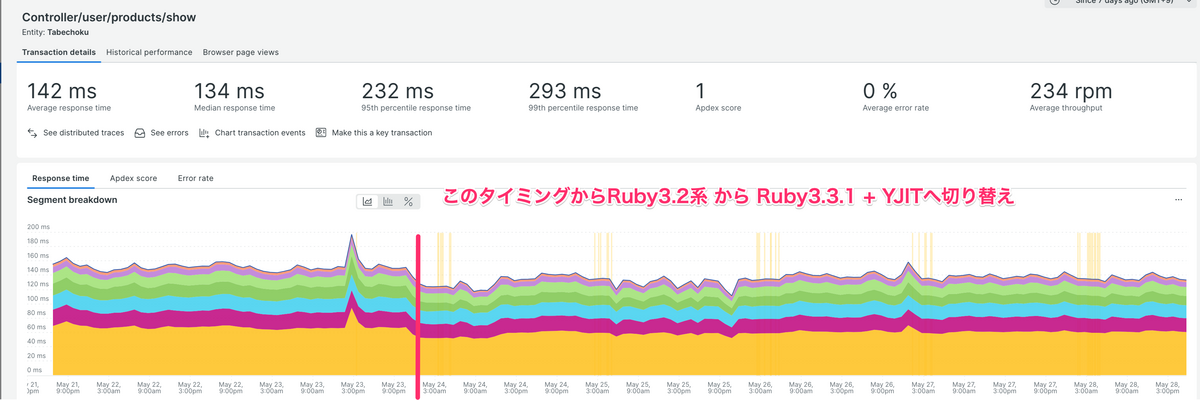
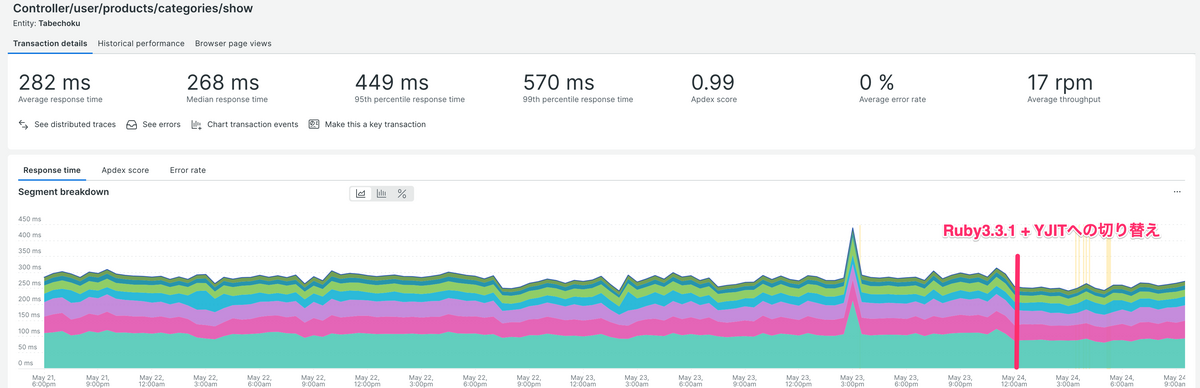
2024年11月、食べチョクアプリのFlutter化が無事完了しました。この機会に、プロジェクトの背景、進行過程、学びについてお伝えします。
Flutter化の背景
導入前は、アプリ開発をiOSとAndroidそれぞれで行っていたため、開発工数が二重で発生しており、かつ差異が生じていました。そこで、Flutter(複数のプラットフォームに対応したアプリケーションを一つのコードで開発できる)を導入し、根本的な開発工数削減と、これまで以上に新しい取り組みを実現できる状態を目指すこととなりました。
Flutter化前の状態
デザインマスター(Figma)
- ページによってデータがあったりなかったりの歯抜け状態😞
- 実装とデザインマスターに差がある(でもしょうがないよね)状態😞
- iOS版を基盤に作成されており、Androidは「よしなに」状態😞
実装
- iOSとAndroidで二重開発😞
- AndroidはiOS版のデザインを見て「よしなに」作っていた😞
- インタラクションは「よしなに」作っていた😞
Flutter化=アプリの開発コードの刷新が主題ではありますが、Figmaで作られている食べチョクアプリのデザインマスターにも様々な問題が発生していました。デザインデータ自体の見直しもミッションの1つとなり、そこでUIデザイナーとして私がアサインされることになったのです。
Flutter化の取り組みに関わったメンバー
UIデザイナー
コンポーネント、マスター、インタラクションの作成を担当
- 私
- 通称ずっきーさん
トークン作成
- デザインチームのマネージャー 松久さん
- 外部の協力会社のデザイナーさん
アプリエンジニア
- iOSエンジニア
- Androidエンジニア
※本記事では、UIデザインやマスターデータに関することを主にお伝えするため、エンジニア・QA・プロジェクトオーナー等は要約しています。
私は何者?
2023年11月に食べチョク(株式会社ビビッドガーデン)へUIデザイナーとしてジョインしました。これまで、グラフィック、WEBデザイン、ディレクションを経験してきましたが、前職はディレクターとして動く場面が多かったため、Figmaの使用歴も約6ヶ月間程度と自信を持って使いこなせているとは言えない状態でした。また私自身は、前段の背景にもあるFlutterの導入の議論に参加しておらず、実働決定後にアサインされています。

というのも「Flutter?Material3って何?」と問い返してしまうほど、アプリデザインの経験や知識はほぼ皆無に近い状態でした。
で、デザイナーは何をしたのか?
- 食べチョクアプリで実存している全ページのマスターデータを作成
- デザインマスターを正として実装との整合性を確保
- デザインフレームワークのMaterial3を元に
- トークン(色、スペーシング、タイポグラフィ)を作成
- コンポーネントを作成
- 個別でインタラクションを設定
前述の通り、デザインデータは歯抜け状態でガイドラインも明確な定義がない状態にありました。理想をいえばオリジナルのガイドラインを設定したいところではありますが、今回の取り組みはあくまで開発環境を整えるスタートに立つためのものです。 最短でガイドラインを設定するためにも、まずはGoogle が提唱しているMaterial Design 3をベースにトークン・コンポーネント・インタラクション等を設定していきました。

「設定していきました」とさらりと書くとそれまでですが、Material Design 3をベースとするためには事前にインプットする作業が必要になります。正直に言うとそのインプットが本当に苦しい苦しい時間でした。Material Design 3という教科書を読み、それを現状のデザインに当てこんでいくという作業を、コンポーネントの1つ1つに対して設定するのです。
取り組みの振り返り
2023年の8月に議論をスタートしたFlutter化は、2024年11月にリリースすることができました。最初から最後までエンジニアの皆さんはそれはそれは大変な偉業を達成されましたが、そこはエンジニアの皆さんによって語られることを期待して割愛します。
😞BAD(反省点)
- マスター作成初期時点はトークンをあまり理解できていなかったので、後々エンジニアから指摘が多々あった
- それぞれのカラーに設定した「意味」を考慮せず、見た目だけで設定してしまったことが原因
- スピード優先 & 現状前提でマスター作成をしたため、UIデザインの改善は最小限に止まってしまった
- エンジニアからのコメントに対して返信漏れ等が多発したため、コメントの使い方は見直しを実施することに
- コメントの中身が即座に解消できる問題であれば「✅解決」で残さない
- 時間がかかるものはissue化をする

放置されてしまったコメントの一例
☺️GOOD(よかった点)
💪経験値💪
- トークンの設定を外部デザイン制作会社に協力を依頼して完成させた
- Material Design 3の知識があるメンバーがいなかったため、一から学びながらやるのではなく知識がある人に協力をあおぎ、スピードと精度をUP

- Material Design 3の知識があるメンバーがいなかったため、一から学びながらやるのではなく知識がある人に協力をあおぎ、スピードと精度をUP
- インラクション設定の際にMaterial Design 3を読むことが必須となった為、苦しいながらもインプットをすることが出来た
⚙️運用面⚙️
- トークンを設定することでデザイナーとエンジニアの認識の齟齬がなくなった
- エンジニアから「とても開発しやすかった」という声多数

- デザイナー同士で各ページやコンポーネントのデータ作りのレベルまで相互のレビューとFBを行ったこと

- Figmaの機能/知識を吸収できる
- トークンの設定漏れを防ぐことができる
- コンポーネントの命名をなんとなくでつけず、命名規則から見直しを実施
- Material Design 3を基準に制作するという前提が関係者の中で共通認識が取れている
- 各個人の主観ではなく、Material Design 3を元にUIデザインのあるべき姿を検討することが出来た
最後に
実は、リリースされるまではデザイナーが行ったことの影響範囲を私自身があまり理解できていなかったのです。ところが、Flutter化の振り返りを実施した際にエンジニアの皆さんから「トークンやマスターの作成があるおかげで実装しやすかった」とお褒めの言葉をたくさんいただき「そうなのか😳」と影響範囲を実感することができました。
デザイナーの中でもフロントに強いデザイナーが存在していたことで、今回のような実装までを考慮したデザインマスター作成まで一歩踏み込んで考えることができたのではと思っています。
デザイナーもエンジニアも未経験の分野を学びながら、議論しながら、頭を抱えながらの取り組みは、難しくも良い経験と自信になったといえます。
効率的なアプリ開発の基盤が整ったので、さらにより良いサービスを提供できるようにこれからもチームで前向きに取り組んでいきます。